Since close to 15 years, I've been using Google products for most of my daily tasks. That includes from Gmail to Contacts Management, from Calendar to Google Keep, from Google Drive to Google Tasks. It's very convenient, it has excellent synchronization across devices, excellent search and much more. Of course the downside is that they know way way too much about me and at some point that's enough. So a few weeks back I decided to look for alternatives and slowly get out of Google.
First thing I needed to solve was email. My setup was to manage all my emails (two personal, four work) from Gmail. Using labels, snoozing and archiving was a great way to organize my work for the day, so I needed something similar. Inspired by Derek Sivers excellent article "Have a private email account", I decided to have a generic Gmail account (without using my full name) to be used in social media, Internet sites, etc and a very private email used only with friends & family. That's in addition to all my work emails. After looking for some alternatives I decide to use mailbox.org for my private email. They offer the option to use my domain and in addition to email offer contacts management, calendar, storage, etc. With 1 euro/month the price is worth. Next issue to solve was the email client for mobile (Android) and desktop (Windows). That turned out to be difficult and complicated. My requirements included:
- Manage multiple accounts including gmail
- Support for CardDAV protocol (so I can sync my contacts across devices)
- Calendar integration and support for CalDAV
- Integration with other platforms such as Slack, Todoist, Trello, etc.
- Easy way to archive emails and maintain Inbox Zero
- Snoozing support
These features would be nice in mobile, but are very very important in desktop. After testing some alternatives, I settled (for the moment) to use Outlook for Android in mobile. I'm not very happy, but that's the best I could find. For desktop, I spent much more time testing alternatives and crossed out Thunderbird, Microsoft Outlook, Hexamail, Claws Mail and more. Only Mailbird, EM Client and Postbox made my final list and here are my notes on them:
Mailbird
+++ Nice integration with todoist/slack/others
++ Snooze feature
+ Archive support
- Kind of expensive ~40 euro with coupon
-- Slow sync with server
-- No CalDav support, maybe it works with Kin Calendar (has support for google calendar)
--- No CardDav integration (only gmail/exchange!!!), alternative to import contacts.
EM Client
+++ CalDav/CardDav Integration (Native)
+ Nice UI
+ Fast sync
- Kind of expensive $50
- No todoist integration - use separate app (maybe widgets?)
- No snoozing - use todoist/categories
-- No archive support (can use move to folder shortcut). Planned for v8, 1st quarter 2020
Postbox
+++++ Great UI
++ Support Archives
- No snoozing - use todoist
- No todoist integration - use separate app (maybe use home button)
- messed up threads
-- Must pay $30/year - a bit too much
-- No Calendar - ???
--- No CardDav support :( - import contacts regularly
Even though, I really liked Postbox great UI and Mailbird archive and snooze support, I did settle for EM Client at least for now. Lack for CardDAV was a deal breaker for both Mailbird and Postbox. Until now EM Client seems solid and using some workarounds I have emulated manual snoozing (using categories), archiving (using move to folder) and todoist integration (using widgets). With CardDAV support from EM Client, Davx5 app for Android and mailbox.org support for contact management, I did solve contacts issue as well. Next in list are notes :)
I've tried in 2013 (see here) to predict elections in Albania and I was completely off :) However, since I like to do some analysis/predictions, I'm doing something this year as well. But I'm not sharing my super-advanced, sophisticated algorithm; I will just share my prediction:
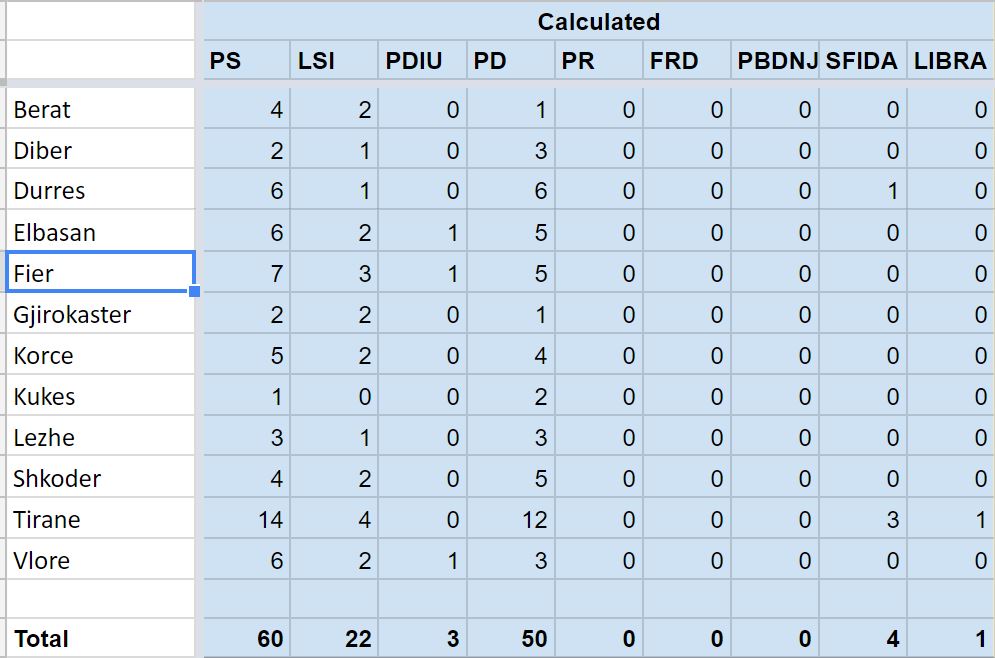
Since based on the prediction, there are some close results, the potential changes are:
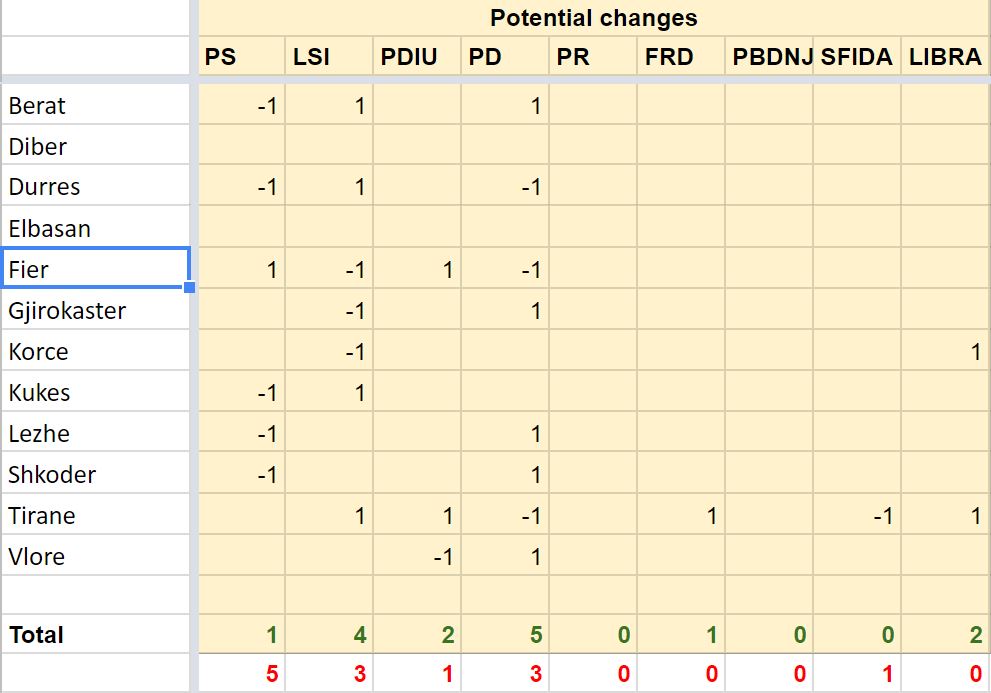
If we take the changes into account and do the totals, we have:
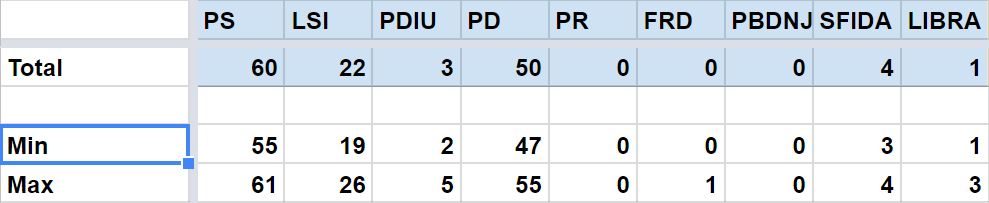
So it's very likely that PS will with the elections, but no party can win the necessary 71 seats to form the government. Everything will be decided by the post elections coalitions. In 4 weeks time, we'll know if I'm right this time :)
The last few decades communication has changed dramatically. From fax and fixed line phones, now we have mobile phones, SMS, instant messaging, email and more. Basically now it is possible to have instant communication with anyone in the World. However being possible and doing it are not the same and unfortunately too many people abuse it. There are numerous studies that show that if you are interrupted from doing something you need 10-30 minutes to concentrate again (check this out). So if you get like 5 calls per day it means that you waste 25% of your time! That's a huge waste of time and money and very few people are actually paying attention!
Now to get some work done, you need to communicate with other people. However, you have to do it minimizing the impact for both you and the other party. My simple rules for this are:
- Except if you're getting a heart attack, send an email first. This give the chance to the other party to read it when they want and not get distracted. On the other hand check the email only in regular intervals (I'm guilty of breaking the rule, but that's what I try to do).
- If it's urgent (and I mean urgent!) and you're not getting a reply in email send an instant message to the work instant messaging app (like Skype).
- The above should cover 99.99% of cases. In the remaining cases:
- Send a SMS to let the other person know something is urgent and needs attention.
- Call her/him only if you don't get a reply.
Of course the rules above do not apply for normal office communication. It does not make sense to email the person next to you to ask for simple answer; common sense should prevail.
You may say this is reasonable, however what do do when my boss calls me? Or when a customer calls? Well, I don't have a silver bullet, but here are some guidelines. The people you communicate with, pretty much fall in one of the following groups:
- Subordinate - this is the easiest one. Make the rules clear to them and they will follow them :)
- Colleague - you can't make rules for them, but you can point it out. If they call you for something that can wait, say "Please email it to me, I'm busy right now". After some time, they should get the lesson.
- Superior - that's a tricky one. If he does not value your time, probably he's not the right boss to work for. However you can try and explain and if he's not listening, look for another job!
- Third party - except for customers (below), you can force standard email communication. There may be some exceptions, but on the long term you can settle with email.
- Customer - in the initial phase you can't do much. But once you have a contract in place be very careful about means of communication. Put a premium price for a call so it's worth the distraction.
In the end: Anytime you need to communicate with someone ask yourself: Does this requires a call? Can I send an email? Instant Message? SMS? If people would be more careful, I'm sure a lot of time and money could be saved!
Recently I had to clone an existing VM in Google Cloud. Unfortunately there's no built-in functionality for this and the suggestion/documentation has some pitfalls. The basic process is:
- Prepare your instance for cloning (In case of Windows machine run gcesysprep utility)
- Create a snapshot of OS disk and all other disks
- Create a new instance by selecting the snapshot of the OS disk and adding snapshots from other disks
- Start the new instances
The above is supposed to be the safest way, instead of doing a snapshot "on the fly" when the instance is running. However I found out that gcesysprep actually did break:
- Installed SSL certificate. Any installed certificate in the old server will not work in the new instance. If you're hosting HTTPS sites that's a big issue. You will need to export the certificates first and reinstall them again.
- Timezone was not restored correctly. Easy to fix, but if you don't pay attention you may run into issue.
I did some other tests using "on the fly" snapshots and didn't have any issue. So my recommendation is to take "on the fly" snapshots of all disks (Enable VSS), create a new instance from the snapshots and you're fine to go :)
As more and more infrastructure is moving to the cloud, the need to make the migration as painless as possible has increased. Typically there are three scenarios:
- Moving a physical machine to the cloud
- Moving an virtual machine from local infrastructure to the cloud
- Moving a machine from one cloud provider to another
Depending on the scenario above, the operating system and on the cloud provider there are different options. Recently I had to migrate some machines (Windows and Linux) from Microsoft Azure to Amazon EC2. Fortunately Amazon EC2 provides import/export functionality (see https://aws.amazon.com/ec2/vm-import/). Unfortunately it has limitations on what it can import and there's no straightforward way to import directly from Microsoft Azure. Since I did go through the pain of doing it, I'm sharing below the necessary steps:
- The first thing you have to do in any scenario is to somehow create a image of the existing machine. If your machine is in an existing local virtual infrastructure (such as HyperV or VMWare) that's easy. If not, you have to look for alternatives and depending on your OS they are:
- In Windows, you can use VMWare Converter (download from http://www.vmware.com/products/converter.html) to create an image from a machine running anywhere. Just install it in the machine that you want to create an image and follow the steps. IMPORTANT: In case of importing to Amazon EC2 you should select only the OS disk, because it's not possible to import a machine with several disks. You can import the remaining disks after the machine is running in EC.
- In Linux, there are several tools, but you can stick with dd builtin utility. You have to do a image of the operating system disk (careful, disk not partition). If OS disk is /dev/sda the command would be:
dd if=/dev/sda of=/backups/os-sda.img
- After you have the image, next step would be to make it compatible with Amazon EC2 import utility. According to the documentation (see http://docs.aws.amazon.com/vm-import/latest/userguide/vmimport-image-import.html#prerequisites-image) it supports OVA, VMDK, VHD and RAW format. In theory the image created in step one should work, but since internally there are different options for VMDK or RAW format, they do not work. What I found out to work was converting them as below:
- In Windows convert the VMDK file to VHD. You can use StarWind V2V Image Converter (see https://www.starwindsoftware.com/converter) to convert from VMDK to VHD. After installing it follow the wizard and you will have your image in VHD format.
- In Linux convert the RAW file to VMDK. Qemu tools (see http://www.qemu-project.org/) will do the job. After installing them, run
qemu-img convert -pO vmdk /backups/os-sda.img /backups/os-sda.vmdk
When it is finished you can transfer the vmdk file in a Windows machine and there you can use the StarWind utility to create a VHD image ready to import in Amazon EC2.
- Next step is to actually import the image. For this first you have to install and configure Amazon EC2 API Tools (from https://aws.amazon.com/items/351?externalID=351) . IMPORTANT: Do not confuse them with AWS CLI Tools (https://aws.amazon.com/cli/). Documentation from reference (at https://awsdocs.s3.amazonaws.com/EC2/latest/ec2-clt.pdf) is very straightforward. After you have setup the EC2 API Tools, the command to import is:
ec2-import-instance "D:\temp\os.vhd" -f VHD -t t2.2xlarge -a x86_64 -b test -o access_key -w secret_key
The meaning of the parameters is:
- -f VHD - Image format is VHD
- -t t2.exlarge - Type of instance to create in EC2 is t2.2xlarge
- -a x86_64 - Architecture is 64 bit. In case of 32 bit, you should use x86
- -b test - Bucket where the image will be imported is named test. You have to create a bucket first in S3 and use that name here.
- - o access_key and -w secret_key are the access key and secret key to access your AWS account.
If the import is successful, you will get a message similar to:
Average speed was 74.650 MBps
The disk image for import-i-fh2e5d1c has been uploaded to Amazon S3
where it is being converted into an EC2 instance. You may monitor the
progress of this task by running ec2-describe-conversion-tasks. When
the task is completed, you may use ec2-delete-disk-image to remove the
image from S3.
As explained, by using:
ec2-describe-conversion-tasks
you can check the progress of conversion. After it is finished, you will see the instance in EC2 console and you can work with it, the same as with other instances.
As you can see there are a few steps to follow, but still it's a better way that to configure everything from scratch, especially if you're importing machines with a lot of configuration details. As a final note, the above will work even if you're running Microsoft SQL Server with databases in different drives (as I did). After starting SQL Server some databases may have issues and you can recover them or use a backup to restore. In any case the final step would be to use xSQL excellent Schema and Data Compare utility to synchronize the databases in new machine with the old one.
Some time ago a friend introduced me to Varnish Cache, an excellent caching HTTP reverse proxy. In simpler terms, it's a piece of software between the browser and the back-end server that intercepts (and potentially cache) every request made to the server. It runs in Linux, but that should not stop ASP.NET developers using it. You'll need some basic Linux skills, but with Google's help it's easily doable.
Recently, I moved a few sites to use it and there's a very noticeable performance improvement. Along the road, I learned some things which I'm sharing here. If you're designing a new site and you expect some traffic (more than a few thousand hits/day), you should definitely design it with the intention of supporting a caching HTTP reverse proxy. However in most cases we have to maintain/improve existing sites and in these cases you have to dig dipper into Varnish and HTTP protocol details to get things working. Some things to keep in mind, especially if you're using ASP.NET in back-end are:
- You can use a single Varnish instance to server multiple sites. For this to work, first you define all the back-ends in your VCL file. Next in vcl_recv sub-routine, you set the correct back-end depending on the request (typically the host), with something along the lines:
if(req.http.host == "example1.com")
set req.backend_hint = "backend1";
if(req.http.host == "example2.com")
set req.backend_hint = "backend2";
- In anything, but very simple configurations, you have to learn a bit of VCL language and to use varnishlog. VCL is pretty straighforward for a developer, but varnishlog is your friend to debug it. It will show all the details of requests and responses going through varnish and at first it may look difficult to trace the details. However if you combine it with std.log() and grep you get useful info. To use std.log() you have to import the std module by using import statement in top of your VCL file. Anything you log using std.log() will go to varnishlog along with everything else that's being logged by default. To distinguish your logs, you can use some special string in the beginning, for example
std.log("AT DEBUG - Request for...")
and then using grep to get only your debug messages
varnishlog | grep "AT DEBUG"
Another helpful tip is to debug only request from your machine. For this you can test client.ip inside vcl_recv, like:
if(client.ip == "185.158.1.35") {
req.x-at-debug = "1";
std.log("AT DEBUG - recv URL: " + req.url + ". Cookies: '" + req.http.Cookie + "'");
}
At the same time, I'm setting a new header (x-at-debug), so I can test against it in other routines (for example vcl_backend_response).
- One of the biggest issues you're going to face with existing websites is handling of user specific content. Most websites have some section where users can login and access some additional content, manage they profile, add items to shopping cart, etc. You certainly don't want the shopping cart of one user to mix up with another user. Without varnish we take it as a given the session state and use it to manage any kind of user specific content. However behind the scenes, session state is made possible by cookies and varnish and cookies are not best friends! To understand this, you have to read a bit more about hashing and how Varnish store the cache internally. By default Varnish will generate the key based on the host/url combination, so cookies are ignored. While it's relatively easy to include cookies in hash, that's a bad idea. In a simple request to one of the websites I tested, the request cookie field contains the following among others:
_gat=1; __utmt=1; __asc=2990a40415733b8f022836a9f7f; __auc=e3955e251562dd1302a38b507f9; _ga=GA1.2.1395830573.1469647499; __utma=1.1395830573.1469647499.1474034735.1474041546.90; __utmb=1.4.9.1474041549617; __utmc=1; __utmz=1.1473756384.78.8.utmcsr=facebook.com|utmccn=(referral)|utmcmd=referral|utmcct=/
As you can see, these are third parties cookies from Google Analytics, Facebook, etc. Chances are the users will have similar cookies. If you hash all of them, you end up with different versions for each user and pretty much Varnish will be useless! The solution is to include cookies in hash, but to be very careful of what cookies you will use. The place to do this is in vcl_recv and you'll have do some work with cookies. The approach I have used, is to have a "special" cookie any time a user is logged on (for example "__user=1". Inside vcl_recv I do a test for this cookie and if found, return pass, meaning do not cache it:
if(req.http.Cookie ~ "__user=1")
{
# AT: Add extra header so we do not strip any cookie in backend response
set req.http.x-keep-cookies = "1";
return (pass);
}
Also, as you can see in the comment, I add an additional header "x-keep-cookies", so that I can do the same test in vcl_backend_response:
if(bereq.http.x-keep-cookies == "1")
{
#AT: We should pass the response back to client as it is
return (deliver);
}
For all other users, I strip all cookies using unset req.http.Cookie in vcl_recv and unset beresp.http.set-cookie in vcl_backend_response. This is all fine except if you're using session state for not logged in user. Next item tackles this issue.
- Typically in a large website, session state is used heavily, not only for logged in users, but for all users. For example you can keep shopping cart items in session before the user has logged in, or you may keep a flag if a user is shown a special offer the first time he gets in the site. Again, this works fine without Varnish, but will break with the above configuration. The reason is that ASP.NET session cookie (the same applies to PHP and other technologies) will get removed and the users will get every time a new ASP.NET session. To work around this issue, you should not use session state for users that are not logged in. Instead you have to rely on cookies to track the same thing. To make things easier, you should name all cookies that you want to keep in Varnish using the same prefix, for example "__at" and add logic in your VCL file to keep these cookies both in request and response. In vcl_recv, you can do the trick with some regular expression:
set req.http.Cookie = ";" + req.http.Cookie;
set req.http.Cookie = regsuball(req.http.Cookie, "; +", ";");
set req.http.Cookie = regsuball(req.http.Cookie, ";(__at.*)=", "; \1=");
set req.http.Cookie = regsuball(req.http.Cookie, ";[^ ][^;]*", "");
set req.http.Cookie = regsuball(req.http.Cookie, "^[; ]+|[; ]+$", "");
Things get more complicated in vcl_backend_response. When you set a cookie from your backend (using Response.Cookies.Add() in ASP.NET), it is translated to a Set-Cookie HTTP header. If you set a few cookies you'll have several Set-Cookie headers and Varnish will give you only the first one when you access beresp.http.set-cookie (a flaw in my opinion!). I spent a lot of time around this issue, until I found it. The solution is to use Varnish Modules, specifically the header module. After you import the module, it's easy to remove all Set-Cookie headers, except those starting with "__at" with something like:
header.remove(beresp.http.set-cookie,"^(?!(__at.*=))");
- Another heavily used method in ASP.NET is Response.Redirect(). It's a very simple method that will redirect the user to a new page. Behind the scenes it's translated into a 302 HTTP response header. However if you have some logic behind, for example to redirect users to a mobile site, if they are coming from a mobile device, it will mess up with Varnish. The reason is that even a 302 response will get cached by Varnish and next user coming from desktop may get redirect to the mobile version. There are two options to solve it:
- Do not cache 302 response, maybe cache only 200 response.
- Do not use Reponse.Redirect() with logic behind. In the above scenario is better to redirect the users in the client side (by the way there's a excellent JS library here). I would prefer this second option.
- For performance reasons, Varnish does not support HTTPS, so you can only cache content going through HTTP. So what about an e-commerce site that has both normal and secure content? If you have the secure content in a separate sub-domain, it's easy to use varnish for the public part and leave the rest unchanged. However if that's not possible, there's an alternative:
- Set Varnish to listen only to HTTP protocol (port 80)
- Install nginx and use it as a reverse proxy to listen only for HTTPS (port 443). Configure the SSL certificates in config file using ssl_certificate and ssl_certificate_key directives and use proxy_pass directive to pass the request to the backend server. The config file for the site will look something like:
listen 443 ssl default_server;
listen [::]:443 ssl default_server;
ssl_certificate /etc/ssl/certs/example.crt;
ssl_certificate_key /etc/ssl/private/example-keyfile.key;
ssl on;
ssl_session_cache builtin:1000 shared:SSL:10m;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_ciphers HIGH:!aNULL:!eNULL:!EXPORT:!CAMELLIA:!DES:!MD5:!PSK:!RC4;
ssl_prefer_server_ciphers on;
server_name www.example.com;
location / {
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
# Fix the .It appears that your reverse proxy set up is broken" error.
proxy_pass https://backend.example.com;
proxy_read_timeout 90;
proxy_redirect https://backend.example.com https://www.example.com;
}
If you have set a password for your key file (as you should), you have to save it a a file and use "ssl_password_file /etc/keys/global.pass" directive so nginx can use it.
- After having Varnish running you'll have to check the status and maintain it. Some useful recommendations are:
- Check how Varnish is performing with varnishstat. Two most important indicators are cache_hit and cache_miss. You will want to have as many hits as possible, so if your numbers don't look good, check the config file.
- Another similar tool is varnishhist which will show a histogram of varnish requests. Hits are shown with "|", while misses with "#". The more "|" you have and the more in the left they are the better.
- To manage varnish, there's the varnishadm tool. It has a few command, but the one most used is to check the backend status. Run "varnishadm backend.list" to check the status of all your server backends.
- If you're used with checking IIS log files, the equivalent is varnishncsa tool. It will log all request and you can even customize it to include HIT/MISS details and check what URL's are getting misses and you may need to cache.
To summarize Varnish is a excellent and very fast tool. I would highly recommend it to anyone developing/managing public websites.
As a final note, Mattias Geniar templates are very useful to get started and helped me a lot. You have to check them out.
CodeProject
Recently I have moved a dozen websites and web apps to Azure. Some are small apps used by a few user with a few database tables, while some are public sites visited by tens of thousands of visitors every day with big databases (tens of GB). I've learned quite a bit during this process and below are some of the things to take into account, if you're going to do something similar:
- Check carefully hard disk performance and max IOPS supported by each virtual machine. If you have a I/O intensive system, you'll need premium disks. Standard disk performance is poor, especially on basic machines (max 300 IOPS).
- Bandwidth is expensive. 1 TB of outgoing traffic will cost you around 80 euro, so if you have a public website you have to use a CDN for most resources (especially images). Otherwise you're going to pay a lot just for the bandwidth.
- There's no snapshot functionality for VM. You have to manually manage backups (using Windows Server Backup for example). Microsoft should have this a priority.
- For databases Basic and Standard options are useless except for very small apps. If you have more than 4-5 databases look at Elastic Pool. They have a better performance and are cheaper (if you have more than a few databases).
The process itself of moving websites it's pretty standard, while moving databases it's another story. First thing you'll find out is that SQL Server for Azure does not support restore functionality! So how do you move database to Azure? If you check the official Microsoft documentation, your options are:
- SSMS Migration Wizard, works for small databases as pointed out by Microsoft itself
- Export/Import through BACPAC format, which is cumbersome and works only for small and medium databases. You have to export from SSMS, upload it to a blob storage (standard, not premium) and then import it from there.
- Combination of BACPAC (for schema) and BCP (for data) which gets complicated.
Fortunately I didn't have to go through any of them. I have used xSQL tools for database comparison and synchronization for a few years now and they are the perfect option to migrate your databases to Azure. The process is straightforward:
- Create a empty database in Azure.
- Use xSQL Schema Compare, to compare the schema of your existing database with the new empty database in Azure. In comparison options you can fine tune the details. For example I do not synchronize users and logins, because I prefer to manually check the security stuff. After comparison it will generate the synchronization script that you can execute directly in Azure and your new database will have the same schema as the existing one.
- Use xSQL Data Compare to compare the data. Since both databases have the same schema, it will map all tables correctly (The exception is if you have tables without a primary key, which you shouldn't! Still, if for some reason you have one, you can use custom keys to synchronize them as well) and generate the synchronization script. If the database is large, the script will be large as well, but it will take care of executing it properly. I had some databases in the range of few GB and it worked very well.
In addition to working well, this approach has another very important benefit. If you're moving medium/big websites, it's unlikely that migration will be done in one step. Most likely it will take weeks/month to complete and you have to synchronize the databases continuously. You just have to run schema compare first to move any potential schema changes and then data compare to synchronize the data. If you expect to perform these steps many times, you may even use the command line versions to automate it and sync everything with just one command.
In Overall, Azure still has some way to go, but it's already a pretty solid platform. Some things, such as lack of database restore, are surprising, but fortunately there are good alternatives out there.
Disclaimer: I've known the guys working with xSQL since a long time, but the above is a post from a happy customer. They have really great products for a very good price.
CodeProject
This transfer window Bayern has been pretty active in both directions. Until now the transfers are:
In
- Joshua Kimmich - from Stuttgart
- Sven Ulreich - from Stuttgart
- Douglas Kosta - from Shakhtar Donetsk
- Arturo Vidal - from Juventus
- Pierre–Emile Højbjerg - back from loan Augsburg
- Jan Kirchhoff - back from loan Schalke 04
- Julian Green - back from loan Hamburger SV
Out
- Bastian Schweinsteiger - to Manchester United
- Mitchell Weiser - to Hertha BSC
- Claudio Pizarro - retired
- Pepe Reina - to Napoli
- Rico Strieder - to FC Utrecht
By far the most controversial transfer is Schweini going to ManU after 17 years with Bayern. There are fractions of the fans not being happy at all about the transfer, accusing Guardiola and Rummenigge of destroying the Bayern identity. Peter Neururer (ex Bochum coach) took it one step further (read more). I must confess that I'm the same camp also and think that a strong German/Bavarian core it's a must for FC Bayern to be successful.
If you look at the full squad of 27 players, 12 are Germans which it's not too bad (44%). However looking more closely, if we take out the three goalkeepers, from 24 field players, only 9 are Germans (37.5%). Even more worrying it's the picture of the starting eleven, which very likely has only Neuer, Lahm, Boateng and Muller as starter (36%).
Whenever Bayern has been successful, it had a very strong German core which was the core of the National Team as well:
- 1974, 75, 76 - Maier, Beckenbauer, Breitner, Schwarzenbeck, Hoeneß, Roth, Müller
- 1999, 2000, 2001 - Kahn, Babbel, Helmer, Linke, Matthaus, Basler, Effenberg, Jeremies, Scholl
- 2012, 13, 14 - Neuer, Lahm, Boateng, Badstuber, Kroos, Schweinsteiger, Gotze, Muller
I'm afraid that this full latinization of Guardiola (Dante, Rafinha, Costa of Brasil; Bernat, Thiago, Martinez, Alonso of Spain; Vidal of Chille) will contribute to more German/Bavarian players leaving. There are rumours that it was one of the reasons Schweini left, and Muller has voiced his concerns also (read here). I hope I'm wrong, but my prediction is that although Bayern can/will win the Bundesliga, they will not get far in Champions League.
Since Vettel announced that he will join Ferrari lots of comparison have been made between him and Schumacher. The similarities are quite a few:
- Both of them are Germans and World Champions
- Schumacher joined Ferrari while they were in a big crisis and Vettel joined them in a similar situation
- Ferrari restructured the team back in '96 and is doing the same now
- etc
Now that half of the season is past we can try and do a comparison between Schumacher '96 and Vettel '15. This isn't very straightforward because the cars are not the same, the competition is not the same, etc. but I will try to do an objective analysis.
First we'll try and compare the Ferrari of '96 against Williams '96 which was the class of the field and at the same time Ferrari '15 against Mercedes '15. To do this I will compare the results of the second driver in Ferrari in '96 and in '15, Irvine and Raikkonen.
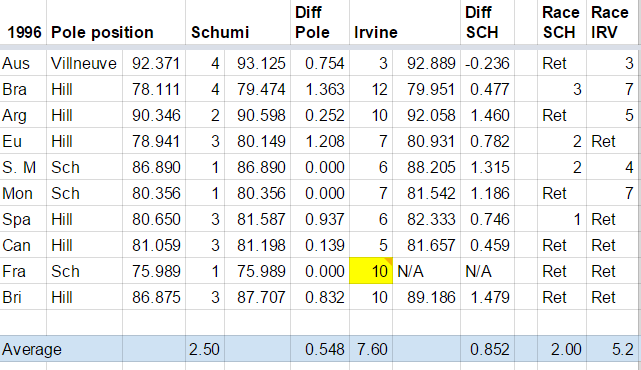
Table 1, 1996 results
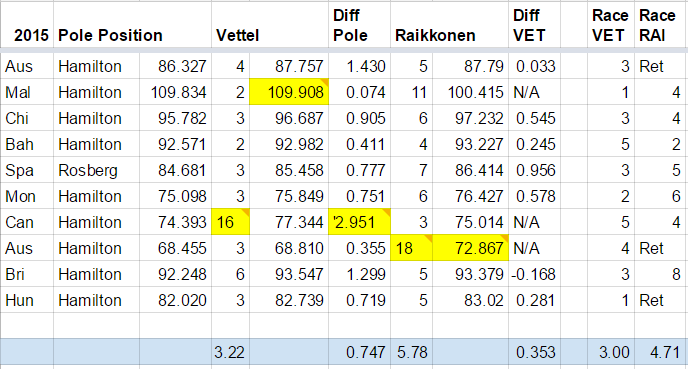
Table 2, 2015 results
In 1996 the average starting position of Irvine was 7.6, while in 2015 the average starting position of Raikkonen is 5.78. In the race Irvine has an average position of 5.2, while Raikkonen 4.71. The difference in both cases is small and taking into account that Raikkonen is a better driver (most people will agree) and World Champion, we can say that on pure performance Ferrari of '96 and of '15 compare similarly to the class of the field (but the Ferrari of '15 is much more reliable).
Now let's compare Schumacher and Vettel performance against the class of the field. Schumacher average starting position was 2.5 with an average difference from pole of 0.548, while Vettel's average starting position is 3.22 with an average difference from pole of 0.747. Additionally Schumacher had 3 pole positions, while Vettel has none. In defence of Vettel, probably the Mercedes of '15 is stronger on one lap pace that Williams of '96, but still it shows that Schumacher is one step ahead. If we compare the race results Schumacher has an average position of 2, while Vettel 3. On the other hand Vettel has 2 victories, while Schumacher only 1 (but he has 5 retirements to Vettel's none). Still the balance is slightly in favor of Schumacher.
Next comparison is between Schumacher '96 and Vettel '15 against their teammates. Schumacher pretty much has destroyed Irvine (qualifying 5.1 positions ahead with an average difference of 0.852), but also Vettel has outperformed clearly Raikkonen (qualifying 2.56 positions ahead with an average difference of 0.353). In both cases their teammates out-qualified them only once (excluding car troubles or rain). In the race Schumacher is 3.2 positions ahead of Irvine, while Vettel 1.71 ahead of Raikkonen.
Last comparison we'll do is the championship position of both after 10 races. In '96 Schumacher was third on 26 points (Hill had 63, Villeneuve 48), while in '15 Vettel is also third on 160 points (Hamilton has 202, Rosberg 181). Vettel is much closer and is still fighting for the championship, but this is mostly because Ferrari of '96 was much more unreliable.
As a conclusion, Schumacher of '96 was really exceptional and is very hard for anyone to compete against him. However the comparison clearly shows that Vettel is doing a great job against a better teammate and better opposition (most will agree that Hamilton/Rosberg are stronger that Hill/Villeneuve).
So well done to Vettel and keep pushing :)
After three unsuccessful tries (2002, 2006, 2010) when Germany lost in the final hurdle (Brasil, Italy, Spain) finally they achieved the most important, glorious reward in Football, THEY ARE WORLD CHAMPIONS for the fourth time in the history! It was a well deserved victory culminating the hard work started by DFB in the beginning of 2000 when Germany hit the lowest point. It has proved once more than with hard work, persistence and a high team spirit you can achieve the maximum.
There's already a lot of information on the web about the final, the statistics, etc, so I'm just putting some links below:
After the World Cup, there are two important news related with "die Mannschaft": First that Toni Kroos moved to Real Madrid, which I believe it will be a huge loss to Bayern. Kroos has really matured in a World Class level.
Second and most important, the captain Philipp Lahm announced his retirement from "die Mannschaft". It will be a huge loss to the team, but it's the perfect choice to retire after winning the biggest price. So I would like to say thank you to Lahm for 10 great years in the National Team and wish him all the best!